Defensive scaffolding for an AI in a
high-consequence domain.
A trading lab built around one invariant: the AI never decides trades. It writes the monthly narrative and flags weird data — that's the entire surface area. A deterministic risk engine, a 7-gate live-trading lock, an audit-vs-broker reconciler, and a drawdown circuit breaker do all the rest.
"Let the AI trade" is the failure mode.
Most retail "AI trading" systems hand the model the buy/sell decision and bolt safety on as an afterthought. Two predictable outcomes: the model produces confident-sounding theses with no real signal, and the safety layers get overridden the first time someone is "behind schedule" on returns. The result is a slow bleed — looking rigorous in the audit while losing money to friction.
This project flips the dependency: code makes every decision, the AI is downstream. If you ripped both AI modules out, the trading loop would behave identically — by design. Removing the AI is allowed; trusting it isn't.
Six layers. Each one can reject what the layer above asks for.
The AI sits at the top of the stack and cannot reach below itself. Strategy is pure rules, deterministic, backtestable. Risk caps are explicit. Execution rejects unsafe spreads. Audit records everything.
buy_hold_spy benchmark for comparison.Seven gates. All must pass before real money moves.
Going from paper to live capital is the highest-stakes state transition in the system. So it has the highest friction.
Mode flag
mode: live in config.
Risk allowance
risk.allow_live_trading: true
Environment variable
TRADING_LAB_ENABLE_LIVE=1
CLI confirmation
--confirm-live flag
Execute flag
--execute required (off by default)
Backtest passes floor
Latest report's config hash matches current config (no tuning-then-switching), Sharpe ≥ floor, drawdown ≤ floor, and Calmar within 10% of the buy-and-hold benchmark.
Reconciliation clean
Audit positions match broker positions.
Real backtest, real stress test, real paper position.
Beats SPY on Calmar by 2x.
Across 16.5 years (2008-2024) — including the 2008 crisis, COVID 2020, and the 2022 bond rout — the v0.2 sector-concentrated strategy delivers 8.45% annualized vs. SPY's 11.07%, with max drawdown of -17.7% vs. SPY's -49.7%. On a Calmar basis (return divided by max drawdown), v0.2 wins 0.48 to 0.22 — over 2x better risk-adjusted performance.
The v0.2 upgrade came from two changes: switching the universe from 5 broad ETFs to 9 SPDR sectors (XLK / XLF / XLE / XLY / XLP / XLV / XLU / XLI / XLB) where rotation is sharper, and concentrating the allocation across the top-6 on-trend sectors with a 30% per-asset cap. Sharpe ratio improved over 6x — from 0.05 in v0.1 to 0.34 in v0.2.
The strategy still excels in clean bull and crash regimes; the synthetic stress harness shows it gets chopped in fast leadership rotations. Knowing exactly where the edges are before deploying capital is the entire point of the harness.
Configurable risk floor, enforced in code.
The live-trading lock holds any candidate strategy to a backtest floor the operator sets. The CLI won't let real money flow until that floor passes — defaults are conservative (Sharpe ≥ 0.5, drawdown ≤ 25%), but a more risk-tolerant operator can raise or lower them deliberately, in writing, never by accident.
Finding a strategy's edges with 16 years of synthetic data costs 30 seconds of compute. Finding them with real money costs months of slow bleed and a hard lesson. The infrastructure is what makes that gap cheap — and what makes adding the next strategy variant a one-class change instead of a rebuild.
The exemplar is the architecture, not the returns.
AI-as-narrator pattern
Demonstrates the right shape for AI in any high-consequence domain — finance, healthcare, infra ops, defense. Code decides; AI explains.
Mandatory backtest + stress harness
You can't deploy without proof. Both historical and adversarial-synthetic. Forces the operator to confront whether the strategy actually works.
Reconciler-first state
Every run starts by comparing audit vs. broker. Drift halts the workflow. The class of failures where state silently diverges between systems just can't propagate.
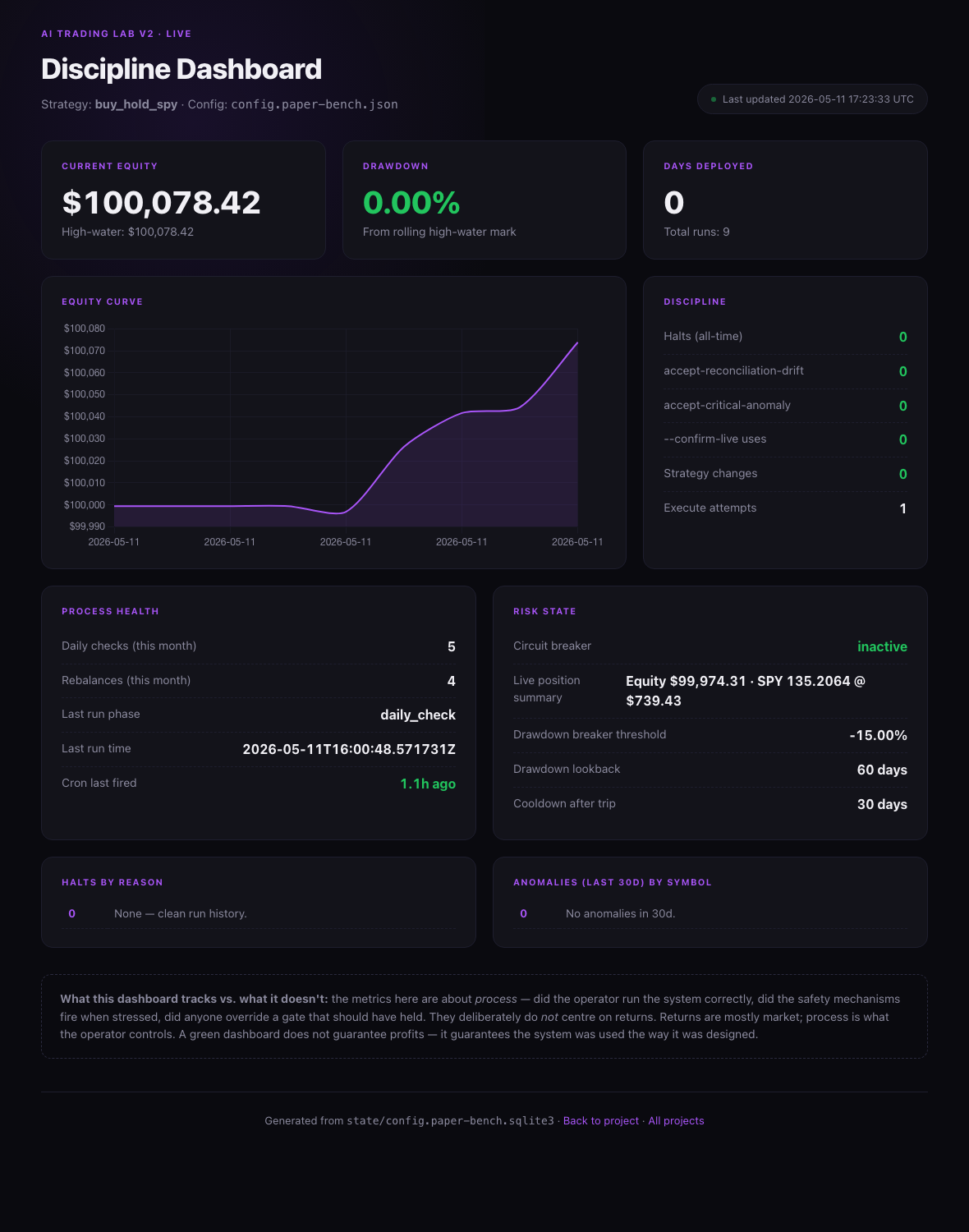
Discipline dashboard
Tracks process metrics — halts, override-flag uses, strategy changes during drawdowns — not return targets. The thing the operator actually controls.
One stack. Many strategies.
The architecture is the artifact — every new strategy plugs into the same safety, audit, and reconciliation rails. The repository is MIT-licensed: clone it, fork it, submit a strategy variant that passes the live-trading floor (Sharpe ≥ 0.5, Calmar ≥ benchmark). If you're hiring for harness or agent engineering, or want to compare notes on AI-in-the-loop systems for high-stakes domains, I'd love to walk through the audit DB, the live-trading lock, and the stress harness with you.
★ Star on GitHub → LinkedIn